3D게임 그래픽스의 커다란 테마로 [음(陰)]과 [영(影)]이 있다. 최근에 [그림자(影)]생성은 Depth Shadow Map 기법이 주류이며, 그림자(影)생성을 위한 섀도우 맵을 여러장 사용하여 그것들을 시점으로부터의 원근에 따라 할당하는 캐스케이드 확장 기법이 주류로 되고 있다. 이러한 어프로치의 그림자(影) 생성은 생성하는 섀도우 맵의 해상도에 의존한 정밀도가 되며, 미세한 그림자(影)를 만들어낼 수 없다.
또 간접광등의 2차광원으로부터의 그림자(影)생성은 현재 쓰이고 있는 방식중에는 절망적이다.
여기서 최근 각광을 받아 온것이 렌더링 결과에 따라 출력되는 Depth(심도)버퍼의 내용을 바탕으로하여
포스트 프로세스 방식의 가상적인 환경광에 대한 그늘(陰)을 생성하는 SSAO(Screen Space Ambient Occlusion)이다
SSAO는
Crytek에 의해 고안되었으며 눈깜빡할 사이에 여러 타이틀에 채택되었지만 그와 동시에 자잘한 문제가 부각되어 왔다. 최근 GDC에서는 이 SSAO의 개량에 관련된 세션이 많이 생겼으며 올해도 예외 는 없었다。「Ambient Occlusion Fields and Decals in Infamous 2」도 그 세션중에 하나 였다. 매우 이해하기 쉬웠고 게다가 구현이 간단해보이니 소개하고 싶다。
■ Screen Space Ambient Occlusion(SSAO)는 완벽하지 않다!
 |
| Nathan Reed氏(Rendering Programmer、Sucker Punch Productions) |
PS3 전용 타이틀인「inFAMOUS 2(인퍼머스 2)」에서는 새겨넣는 형태의 그림자[陰] 로써 버텍스 단위로 차기차폐 상태를 새겨넣는 고전적인 AO(Ambient Occlusion)와 SSAO 양쪽을 사용하여 다양하고 풍부한 "그림자(陰)" 표현을 하였다.
버텍스 단위의 AO와 SSAO는 각각의 단점과 장점을 서로 감싸는 좋은 보완관계가 성립된다. 버텍스 단위의 AO는 움직이지 않는 정적인 오브젝트 그것도 거대한 건물이 만들어내는 대국적인 그림자( 陰(影)) 생성에는 유효하다
이 그림자(陰(影))의 투영되는 곳의 버텍스를 미리 세세하게 해두지 않으면 안되는 귀찮음이 있지만 SSAO에서는 만들기 어려운 광범위의 그림자((陰(影)))를 만들어 내는데에 적합하다. 이것을 보간하는 존재가 SSAO이다
SSAO는 정적인 오브젝트는 물론, 돌아다니는 동적인 오브젝트에 대해서 국소적인 그림자((陰(影))) 생성을 수행할 수 있다. 구체적인 알고리즘은 아래와 같다.
보고 있는 픽셀이 어느정도 차폐되고 있는 장소의 픽셀인가를 , 그 픽셀에 대응하는 Z값과 그 픽셀 주변에 대응하는 Z값을 읽어들여, 그 값 끼리 비교해서 구한다. 그 비교 연산으로부터 깊이 맵(심도 맵)상의 깊숙히 닫혀진 장소에 있는 픽셀일수록 차폐도가 높다고 하고 "그림자(陰)"색을 입힌다.
간지나게 말하면 깊이맵 상에서 초 로컬한 레이캐스팅을 수행하여 차폐상태를 조사하는 수법이라고
할 수 있다.
하지만 SSAO는 결국은 렌더링 결과에 대해서 수행하는 화면좌표계 포스트 프로세스이기 때문에
몇가지 약점이 있다.
우선 렌더링 결과의 바깥둘레 부근은 (심도버퍼의)정보가 부족하기 때문에 차폐도를 제대로 계산 할 수 없다. 그림자색(陰色)이 엷어지는것 뿐이므로 무시되고있는 케이스가 대부분이다
또 깊이 맵은 시점으로부터 본 깊이 정보밖에 저장되어있지 않으므로 무언가에 차폐되고있는 가에 대한배후(背後)의 차폐도는 계산 할 수 없다.
그것과 씬이나 오브젝트에 대해서 시점까지의 거리가 거의 일정한 게임이라면 눈치채기 어렵지만
씬이나 오브젝트에 대해서 시점을 멀리하거나 가까이 하거나 하면 부자연스러운것을 눈치 채게 된다.
그렇다. SSAO에서 입혀진 그림자색(陰色)의 범위(크기)는 화면좌표계에서의 차폐도의 탐색이 수행되는것뿐이므로 그려지는 그림자색(陰色)의 영역은 화면상의 면적에 대해서 거의 일정하게 되버리는 것이다.
예를 들면, 어떤 막대 모양의 오브젝트의 밑부분에 그려진 그림자"陰"색의 크기에 주목을 하고 보면 그 오브젝트에 찰싹 붙을 정도로 가까이서 봐도 멀리 떨어져서 봐도 화면상에 그려지는 밑부분에 그림자(陰)의 크기는 변하지 않는다.
정확히는 가까이 갔을때는 그 막대의 빝부분이 확대해서 보이기 때문에 그 그림자 색(陰)은 크게 보여야 하며, 멀리 떨어졌을때에는 막대가 작게 보이기 때무문에 그것에 맞춰서 작게 보여야 한다
■ AO Fields 방식
 |
| 「inFAMOUS 2」에서 AO Fields 방법 |
「inFAMOUS 2」는 3인칭 시점의 오픈 월드 형태의 액션 게임으로 비교적 카메라가 씬이나 오브젝트에 대해서 가까이 가거나 멀리가거나 할수있는 시스템으로 되어있다.
게다가 초능력을 사용하여 자동차같은 커다란 오브젝트를 집어 던지거나 이동시키거나 할 수 있기 때문에 위에서 말한 SSAO의 약점은 크리티컬하게 보이는 상황이 있다.
그래서「inFAMOUS 2」개발 팀은 SSAO를 독자적으로 연구하여 개량하기로 했다.
그중 하나가「Ambient Occlusion Fields」(AO Fields)이다.
이 방식에서는 각 오브젝트 모델에 짝이되는 AO Fields를 사전 계산을 할 필요가 있다.
AO Fields란 감각적으로 말하자면 [ 그 오브젝트가 모든 방향에서 어떤 다른물체들을 차폐하는 가 ] 라는 정보이다.
이 AO Fields의 크기는 각 오브젝트 모델을 완전히 가리는 직육면체보다도 더욱더 큰 직육면체 로 한다.
이 커다란 직육면체를 xyz 각 축 8~ 16분할하여 복셀로 분할하고 이 각 복셀의 중심으로부터 전방위(6방향)에 대해서 32 x 32텍셀의 큐브맵을 렌더링 한다.
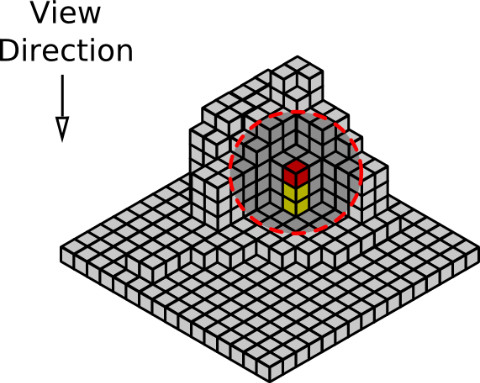
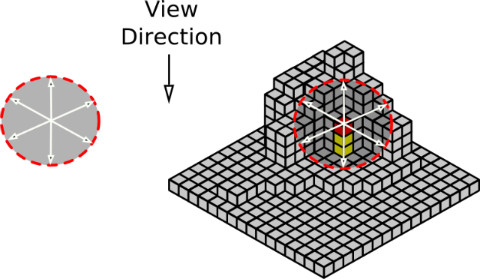
| 【AO Fields】 |
|---|
 |  |
| AO Fields 이미지(왼쪽)、각 복셀에서의 AO Fields는 각 복셀의 중심으로부터 봤을때의 전방위의 배경을 큐브맵으로 렌더링한 결과로부터 얻는다(오른쪽) |
여기까지는 꽤 대담하다. 렌더링 된 큐브맵을 탐색해서 그 중심을 구하고 복셀의 중심으로부터 이 중심으로의 방향을 산출한다. 이것을 차폐 벡터라고 한다. 참고로 여기서 말하는 [ 중심 ] 이라는 것은 큐브맵에 그려져 색칠된 텍셀의 면적으로부터 그 중심을 구하는것 뿐이다. 이것으로 이 복셀의 중심으로부터 본 [차폐 방향≒가장 이 지점이 차폐되고있는 방향]가 구해진다
이 큐브맵에 렌더링된 텍셀의 면적(칠해진 면적)은 이 복셀의 차폐율을 나타내고 있으며 이면적을 바탕으로 [ 이 지점의 차폐율 ]을 구한다.
이렇게 구한 차폐방향(x,y,z)와 차폐율을 텍스처에 저장한다. 차폐방향은 벡터이므로 RGB에 저장하고, 차폐율은 스칼라 이므로 α 채널에 저장한다. 이렇게 계산되었을때 가능한것이 3D 텍스처(3차원의 수치 테이블)로 이것이 그 오브젝트에 짝을 이루는 AO Fields라는 것이 된다.
| 【AO Fields의 사전계산】 |
|---|
 |  |
「inFAMOUS 2」의 AO Fields 방식은 Mattias Malmer의 논문
「Fast Precomputed Ambient Occlusion for Proximity Shadows」을 참조하고 있으며, 이 논문을 참고로 AO Fields의 직육면체 사이즈가 결정되었다고 한다
세션에서는 실제「inFAMOUS 2」상의 오브젝트로 AO Fields를 어느정도의 크기로 잘랐는가도 구체적인 값을 알려주었다.
예를들면 자동차에서는 32 x 16 x 8 의 복셀로 구분지어 각 테이블이 32비트 정수였기에 3D텍스처의 용량은 16,384바이트(16KB)로 되어있다. 마찬가지로 공원의 의자는 16x8x8복셀로 4KB, 쓰레기통은 8x8x8 복셀로 2KB. 3D 텍스처라고 해도 꽤 엉성하기에 의외로 사이즈는 작다. 단 사이즈는 작지만 데이터 테이블은 벡터 데이터이며 정밀도가 요구되므로 텍스처 압축(DXT)는 하지 않았다는 것.
| 【AO Fields의 크기】 |
|---|
 | 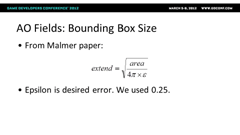 |
| 「다른 물체의 미치는 차폐상태」를 구하므로 오브젝트 사이즈보다도 필연적으로 큰 영역이라고 생각할 필요가 있다. 그림의 회색 상자가 오브젝트를 감싸는 보정된 사이즈의 직육면체라고 했을때 파란 상자가 AO Fields。「inFAMOUS 2」에서는 참고논문을 본 떠ε=0.25를 선택했다 |
■ AO Fields를 사용한 렌더링
 |
| 여기까지를 그대로 구현한 결과. 그림자색(陰色)엉성한 사각형이 되어 나타난다. 이대로는 너무 부자연스럽다 |
실제로 이 AO Fields를 런타임에서 어떻게 이용할까 인데 모든 오브젝트군의 렌더링이 끝난 후에 각 오브젝트의 AO Fields사이즈의 직육면체를 렌더링 해 나가는 형태이다.
라고는 해도 실제로 직육면체의 실체를 그리는것이 아닌 깊이 테스트를 수행하여 AO Fields 사이즈의 직육면체와 모든 오브젝트의 렌더링이 끝난 씬과의 교차부분 ( AO Fields를 적용할수 있는 부분)을 구하는 것이 주된 목적이다.
이것은
Deferred 렌더링의 라이팅 방식과 꽤 닮은 형태이다. Deferred 렌더링의 라이팅 방식에서는「광원의 적용범위」를 구하지만 AO Fields에서는「차폐의 적용범위」를 구하고있는 것이다
실제로 렌더링을 수행한 픽셀 셰이더에서는 깊이 테스트의 결과로 그 부분이 AO Fields를 적용해야할 장소인가라고 판단가능한 경우는 그 깊이 값을 바탕으로 월드 좌표계의 위치정보를 역산하여 그 값으로부터 AO Fields의 어느 복셀의 영향 하에 있는가 ( 오브젝트의 로컬 좌표 )를 구한다.
AO Fields의 어느 복셀을 읽어내면 좋은가를 구하면, 그 복셀에 대응하는 3D 텍스처로부터 차폐 벡터와 차폐율을 읽어낸다. 다음은 그 장소의 법선벡터를 읽어내어( Defferd 렌더링 엔진이라면 깊이 버퍼와 함께 이전에 G 버퍼로써 렌더링이 끝난 상태) 이 방향벡터와의 사각 관계를 검토하면서 차폐율에 바이어스값을 주고 그림자색(陰色)을 산출하면 된다
여기까지의 내용을 실제로 실행한것이 오른쪽에 있는 스크린샷으로 아니나 다를까 엉성한 복셀단위로 관리되고있는 AO Fields의 내용이 사각형처럼 렌더링 결과에 여실히 나타나 버렸다。
| 【차폐도의 산출식】 |
|---|
 | 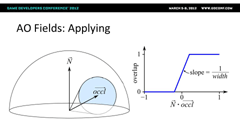 |
| 해당 장소의 차폐도 산출식. Strength는 차폐강도를 나타내며 이것은 아티스트가 오브젝트마다 결정할 수 있다. 즉 AO Fields에 따라 그림자색陰色의 농담을 Strength로 컨트롤 할 수 있다(왼쪽)、해당 장소에 법선벡터가 차폐 벡터의 방향에 가까우면 가까울 수록 그림자색(陰色)은 짙어진다 라는 조정 항목이다(오른쪽) |
■ AO Fields의 개량
 |
| 가장 외곽부분 경계에 있는 복셀을향해 차폐율이 0으로 되도록 AO Fields를 조정. 이 슬라이드에서 alpha는 α채널에 저장되어있는 차폐율을 말한다 |
그래서 각 오브젝트의 AO Fields에 대해, 가장 외곽부분 경계에 있는 복셀의 차폐율을 강제적으로 0으로 하여 AO Fields의 차폐율을 가장 큰 값으로부터 외곽 복셀의 차폐율을 점점 0으로 선형적 감쇠형태의 조정을 한다. 이 조정을 수행하는 것이 이 스크린 샷으로 사각형처럼 보이는 아티펙트는 거의 알수 없게 된다.
| 【AO Fields 조정】 |
|---|
 |  |
| 왼쪽이 조정 전 오른쪽이 조정 후. 사각형같이 보이는 아티펙트는 거의 보이지 않고 있다 |
하지만 아티펙트는 또하나 있다. 그것은 잘못된 그림자색(陰色)이 붙는다라는 아티펙트이다.
알기 쉬운 예로써 자동차의 본네트나 지붕, 사이드 스텝 부근에 불필요한 그림자색(陰色)이 생긴다.
이것은 AO Fields가 꽤 엉성한 복셀 단위로 계산되고있기 때문이며, 오브젝트의 경계면 부근에서는 차폐율이 급변하기 때문에 이 부근에서의 차폐율의 계산을 진행할때 많은 오차가 생겨 버리는 것이다
각 복셀로 차폐 항목을 계산할때에 이 복셀이 경계면에 있을때는 자동으로 차폐율을 조정하도록 하는AO Fields 계산법을 넣어보는 것도 생각해 봤지만 복잡한 형상이 있는 부분에서는 그것도 판단이 어려웠다.
그래서 어쩔수 없이 그림자색(陰色)을 입히는 픽셀 부분에 법선벡터를 참조하여 그 방향에 따라 AO Fields의 참조를 반 복셀 옆으로 땡겨서 조정(오프셋)을 더하는 방식을 채택했다
약간 강인한 대응책이긴 하지만 결과는 썩 좋았다. 경계면 부근에서의 의미불명한 그림자색(陰色)을 없애는데는 성공. 하지만 그 부작용으로써 차폐율이 높은 부분에서의 그림자색(陰色)이 보다 짙게 나와버리게 되었다. 뭐 그렇게 큰 문제는 아니라고 판단..
최종적으로는 이 방식을 채택하는 것으로 결정했다.. 여기까지 내용을 영상으로 종합한 것이 아래에 있는 영상이다
| 【AO Fields 조정 -2】 |
|---|
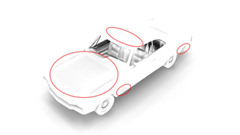 |  |
| 경계면에서의 불필요한 그림자(陰)색。원으로 표시한 부분이 해당 부분이다(왼쪽)。셰이딩 대상 장소의 법선 벡터의 방향에 따라 반 복셀 빗겨서 AO Fields를 샘플링한 방식을 넣는 것으로 아티펙트를 제거(오른쪽) |
■ AO Decals 이라는 발상~ 두께가 얇은 오브젝트를 위한 AO Fields
「inFAMOUS 2」에서는 창문이나 문 같은 두께가 엷은 오브젝트에 관해서는 보다 간략화한 모델의 AO Fields를 채택했다고 한다.
기본적인 방식은 AO Fields와 같으며 대상 오브젝트를 복셀 화 하여 구분하고 각 복셀 단위로 차폐 항목을 구해 나간다는 방식이지만 엷은 오브젝트이므로 대담하게 간략화 한것을 도입했다.
우선 3D 텍스처는 사용하지 않으며 AO 정보는 2D 텍스처로 다룬다. 그리고 복셀의 레이어는 4층으로 한정하고 첫번째 계층의 정보를 R 텍셀에 2,3,4계층의 정보를 각각의 G, B, α 에 저장한다.
각 수치가 스칼라로 되버리므로 AO Fields에 저장되어있던 차폐방향벡터는 버리고, 차폐율만을 저장하도록 하는 것이다. 이 오브젝트의 4계층분의 차폐율을 저장한 텍스처를
AO Decals라고 부른다
AO Decals에서는 차폐방향은 각 복셀에서 동일방향을 가리키고있다 라고 가정되버린다.
예를들면 창문이라면 벽에 붙어있으므로 차폐방향은 벽면으로부터봤을때 옥외 방향으로의 반구방향뿐이라고 생각한다 (반대측은 항상 벽으로 차폐되어 있다고 간주한다)
AO Decals에서도 사전계산으로써 차폐율 계산은 필요하지만 AO Fields에서 했던 각 복셀에서의 큐브맵 렌더링은 사용하지 않으며 보다 간략화한 알고리즘을 사용한다
대상 오브젝트를 텍스처에 하이트맵으로써 렌더링하고, 그 결과에 대해서 4계층분의 레이어로 구분짓고 각 계층의 각 텍셀에 대응하는 하이트맵의 높치값과 그 주변의 높이값을 검토하여 차폐율을 계산한다. 하이트맵을 깊이 버퍼로써 보면 이 방식은 SSAO와 거의 동일하다
SSAO 처리와 다른것은 공중에 뜬 지점에 대해서도 차폐율을 계산하는 점이다. 이 것은 창틀을 걸치는것 같은 제3의 오브젝트에 대해서도 그림자색(陰色) 입히도록 하기 위해서 일 것이다
| 【AO Decals -1】 |
|---|
 |  |
| AO Decals에서는 αRGB의 4텍셀을 4계층의 각 지점의 차폐율로 할당한다. 기본적인 사고는 AO Fields와 같지만 AO Decals에서는 차폐방향은 생략하고 복셀도 4계층으로 한정하고 있다(왼쪽)。오브젝트를 하이트맵으로써 렌더링. 이것에 대해 4계층을 잘라 각 지점에서의 차폐율을 구한다. 차폐방향은 오른쪽 그림에서 말하면 바로위에 반구방향에 대해서 구한다(오른쪽) |
| 【AO Decals -2】 |
|---|
 |  |
| 엷은 오브젝트라고는 해도 4계층은 꽤 엉성한 공간분할이 된다(왼쪽)。차폐율은 오브젝트의 표면상 각지점으로부터 수행된다. 결과는 각 지점에 가장 가까운 계층에 저장되어있는(파란점). 다른 물체로의 차폐에도 대응하기 위해 공중점에서도 차폐율을 계산한다(초록색 점)(오른쪽)。 |
 |
| 「inFAMOUS 2」에서의 AO Decals 방식。AO Decals에서는ε=0.7로써 AO Fields보다도 작은 경계상자를 할당하고있다 |
AO Decal 의 크기도 AO Fields 때와 같이 각 오브젝트가 완전히 들어가 있으며 약간 크긴 하지만 AO Fields때보다도 크기는 작은편이다.
이것은 처리부하에 배려와 오브젝트의 두께가 애초에 엷기 때문에
그정도로 크게 하지 않아도 충분하기 때문일 것이다.
데이터 사이즈로써의 AO Decals는 각 변 64~128 텍셀 정도로 하고 저장하는 것이 스칼라 값의 차폐율 이므로 다소의 오차도 허용할수있다는 것으로 DXT5 압축을 적용하고 있다. 데이터 사이즈로써는 4~16KB이고 AO Fields와 동일하다. 그렇게 크지는 않다.
런타임에서의 AO Decals의 적용은 AO Fields와 완전히 똑같다. 각 오브젝트의 렌더링을 끝낸 씬에 대해 AO Decals 사이즈의 직육면체를 렌더링하여 구해진 교차 부분에서 AO Decals에 저장된 차폐율을 바탕으로 그림자색(陰色)을 입혀 나간다. AO Decals에서는 차폐방향이 간략화되어 존재하지 않으므로 AO Fields보다도 단순하다
단 씬과 AO Decals의 교차 부분의 깊이값에 대응하는 차폐율을 4계층의 슬라이스한 AO Decals의 1계층부터 읽어내는 것 뿐으로는 포인트 샘플링이 되어 지저분하게 되버린다. 따라서 몇가지의 텍스처 필터링을 도입할 필요가 있다. 하지만 단일 텍스처내에 있는 αRGB의 각 수치에 대해서의 필터링 처리라는 것은 하드웨어에서는 불가능하므로 각자 픽셀 셰이더프로그램측에서 수행할 필요가 있다
| 【AO Decals - 3】 |
|---|
 |  |
| 차폐율과 차폐강도 값만으로 그림자색陰色을 결정한다(왼쪽)、AO Decals로부터 차에 위치를 가져올 때의 필터링 처리를 하는 셰이더 코드 예(오른쪽)) |
■ AO Decals의 개량
 |
| 원으로 그린 부분이 하얀선의 아티펙트가... |
라는 것으로 지금까지의 처리를 적용한 것이 오른쪽 스크린 샷이다.
그러나 벽면과 창틀의 교차 부분의 어렴풋이 하얀 선이 보이고 있다.
실은 이부분이 AO Fields에서도 보이지만 엉성한 복셀화의 폐해로
경계면에서의 급격한 차폐율 변화가 생기는 것이 원인이다.
구체적으로는 경계면안쪽이 차폐율 0이고 경계면 바깥쪽이 "높은" 차폐율일 경우에 텍스처 필터링의 효과에 의해 얻어낸 차폐율이 엷어져 버린다는 것으로 인해 생긴다
이것을 막기 위해서는 하이트맵에 숨어 있는 부분에 대한 경계면의 차폐율은 그 주변에 있는 하이트맵에 숨어있지 않은 경계면에 차폐율로 덮어 씌워 버리면 된다. 이것으로 경계면의 차폐율이 급격히 변하게 되지 않게 되어 하얀 선의 아티펙트를 사라지게 할 수 있다
 |  |
| 파란색은 통상의 차폐율을 구한 점. 빨간점은 하이트맵에 숨어있는 특수한 점(왼쪽)、경계부근의 차폐율은 균일화해 버리므로 이 부근에서의 텍스처 필터링에 의한 차폐율의 급격한 변화를 회피한다(右) |
 |  |
| 해당 처리를 적용하기전(왼쪽)、하얀 선의 아티펙트가 사라짐(오른쪽) |
위의 스크린샷은 실은 조금 결과를 미리 보여준 샷으로 실은 아직 벽면에 대해서 직교하는 오브젝트의 측면의 그림자색(陰色)이 부드럽게 되버린다는 아티펙트가 남아있다. 창문의 예를 들자면 마치 측면이 둥근형태를 띄고있는 것 같은 그림자색(陰色)이 되어 버린다는 것이다
이것에 관해서는 AO Decals를 더욱 개량하는것이 아닌 각 오브젝트 측에 배후의 무한으로 퍼지는 벽면 평면이 있다고 하고 각 버텍스의 부가정보로써 이 벽면으로부터의 차폐율을 새겨넣어버리는 것으로 대처한다. 즉 벽면에 직교한느 측면에 나오는 짙은 그림자색(陰色)은 AO Decals의 효과가 아닌 버텍스의 새겨넣은 AO의 효과 라는 것이다. 여기까지 내용을 영상으로 종합한 것이 아래의 영상이다
 |  |
| AO Decals 만으로는 이와 같은 측면에 그림자색(陰色)이 바로 위로 갈수록 엷어져 버려, 마치 둥근형태를 띄고있는 것 같은 음영이 보이게 되버린다(왼쪽)。그림 중간에 있는 식으로 구한 벽으로부터의 차폐율을 오브젝트의 각 버텍스에 새겨넣는 것으로 대처한다(오른쪽) |


|
|
| 도입하기전(왼쪽)、도입한 결과。측면의 그림자색陰色이 확실히 나오게 되었다(오른쪽) |
■ 마치며~ AO Fields의 방식을 몸이 변형되는 인체에 적용하는 방법
 |
| 이후에는 AO Fields 방식을 몸이 변형하는 인체같은 오브젝트에도 적용해 나가는 것을 과제로 하고 있다. 게다가 그것은 결코 꿈은 아니다 |
세션에 마지막에는「inFAMOUS 2」에서 AO Fields와 AO Decals을 도입함으로써 증가한 추가 텍스처 용량의 레포트가 공개되었다。
「inFAMOUS 2」에서는 이 AO Fields 나 AO Decals의 개념을 도입한 유니크 오브젝트는 119종이라고 하며 그것들의 총 텍스처 용량( AO Fields의 3D 텍스처와 AO Declas의 2D 텍스처의 합산용량)은 불과 569KB라는 것。
119개의 오브젝트에 대한 추가 텍스처 용량으로써는 그럭저럭의 증가량으로 이걸로 얻을 수있는 효과를 생각해보면 합리적인 대책이었다라고 할 수있겠다
퍼포먼스적으로는 1프레임당 평균적으로 봤을때 20~100개의 AO Fields, AO Decals의 렌더링 부하가 걸리고 있지만 소요시간은 PS3에서 0.3~ 1.0ms Worst Case라도 2.3ms였다라고 분석되고 있다. 기본적으로는 버텍스부하보다는 픽셀 부하가 높은 처리 이므로 표시 프레임에 대해서 이 방식에 의해 그림자색(陰色)이 그려지고 있을때에 크게 부하가 높아지는 것 같다.
AO Fields, AO Decals는 현재 오브젝트 자신이 변형되지 않는 자동차등의 대도구(大道具)오브젝트, 쓰레기통 같은 소도구(小道具)오브젝트에서 밖에 적용되고 있지 않다. 오브젝트가 움직여도 제대로 그 움직인 부분에다른물체의 차폐는 고려되지만, 손발이 움직이는 인체 같은 그 자체가변형되는 오브젝트에 관해서는 이 AO Fields, AO Decals는 대응하고 있지 않다. 이 부분이 이후 연구해 나가야 할 확장 방향성이라고 Reed씨는 말한다.
단,인체 같이 [ 자신이 변형하는 ] 오브젝트에 대해서의 AO Fields의 아이디어는 Reed씨도 기다리고 있으다.인체라면 팔, 다리, 목, 몸통 같은 주요 인체 구성 파츠를 분해하여 각각의 부위에 대해 AO Fields를 적용한다 같은 연구이다.
즉 변형하는 오브젝트를 변형하지않는 오브젝트의 집합체로써 처리해 준다라는 것이다.
이렇게 함으로써 추가 부하도 리니어 스케일로 어림잡는 것이 가능하다
SSAO를 발단으로 한 새로운 셰이딩 방식은 당분간은 앞으로도 진화를 보여줄 것이며 계속 유행해나갈 것이라고 필자는 생각한다.
 |  |
AO Field와 AO Decals에 의한 추가메모리 사용량(왼쪽)과
추가 GPU 부하(오른쪽) |